Semantic Guidance Tuning for Text-To-Image Diffusion Models
👬 Team: Hyun Kang, Dohae Lee, Myungjin Shin, In-Kwon Lee
👨🏻💻 Role: Primary Author
📅 Date: Dec 2023

Abstract
Recent advancements in text-to-image diffusion models have demonstrated impressive success in generating high-quality images with zero-shot general- ization capabilities. Yet, current models struggle to closely adhere to prompt semantics, often misrepresenting or overlooking specific attributes. To address this, we propose an approach that modulates the guidance of diffusion models during inference, requiring no training or optimization. Specifically, we first decompose the semantics in the guidance into a set of arbitrary concepts and monitor the guidance trajectory in relation to each concept. Our key observa- tion is that deviations in the model’s adherence to prompt semantics are highly correlated with the guidance’s divergence from one or more of these concepts. This highlights that semantic misalignment between the generated image and the prompt can be determined on-the-fly. Based on this observation, we devise a technique to steer the guidance direction towards any concept from which the model diverges. Extensive experimentation validates that our method improves the semantic alignment of images generated by diffusion models in response to prompts.
ConceptDiffusion
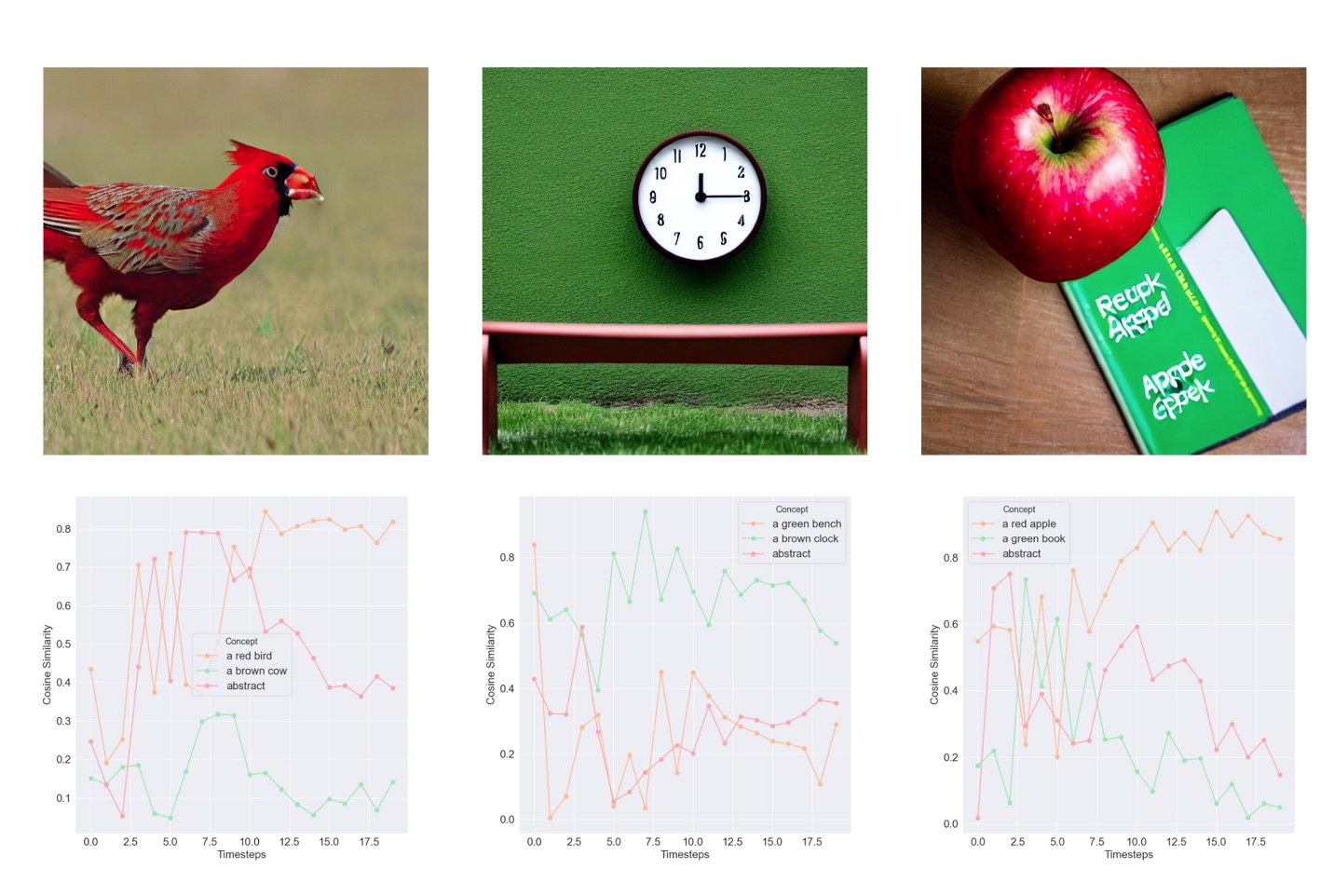
We observe that semantic misalignment between the given prompt and the generated image is highly correlated to the divergence of the noise estimate from one or more concepts that are critical for successful synthesis.
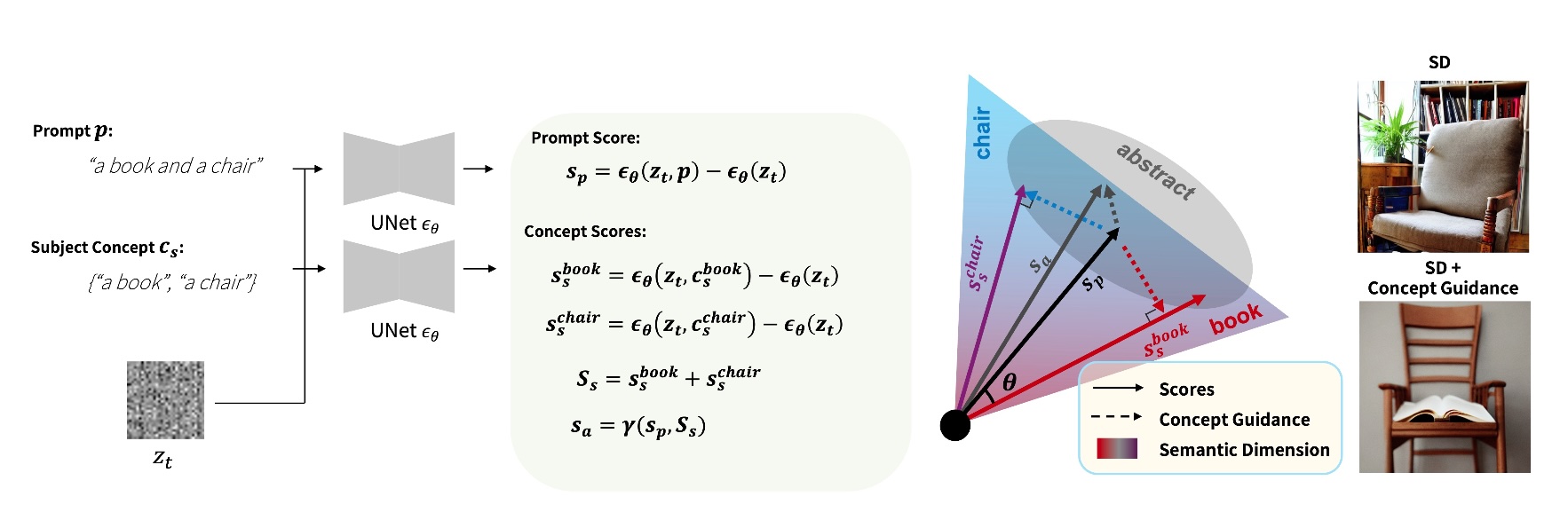
Given a prompt e.g., “a book and a chair”, we extract the subject concepts {“a book”, “a chair”} and compute their corresponding scores. The score for abstract concept is indirectly obtained. The Concept Guidance is then applied based on the cosine similarity between the prompt score and score for each concept.
Results

📝 Paper: Semantic Guidance Tuning for Text-To-Image Diffusion Models
Exploring the future, one post at a time.